Table of Contents
MLWizard
MLWizard is a tool supporting non-experts in developing classification system within RapidMiner. For a given data set, it automatically recommends, constructs, and optimizes a classification process. The user is guided in three simple steps from its dataset to a ready-to-use classification system.
MLWizard implements several meta-learning methods. Based on the knowledge about many datasets, it predict the accuracy of different classification algorithms for the given dataset. Additionally, it provides an improved genetic optimization for the most important parameters of the classifiers by replacing the random start population with already promising solutions.
The meta-learning functionality can also be accessed via the MLWizard API and the .MLWizard Command Line Interface
Installation
The easiest for installing MLWizard is to download it over the RapidMiner update mechanism. For this you click on Help ⇒ Update RapidMiner in the menu bar and select the PaREn Automatic System Construction Wizard for installation. After the automatic installation and a restart of RapidMiner, the functionality of MLWizard is available in RapidMiner.
Alternatively, you can also download and install MLWizard manually. Download the archive and extract its content to the lib/plugins folder of your RapidMiner installation. You can download the software as binary or the source code here. Both packages contain datasets from the UCI machine learning Repository, StatLib, and the book "Analyzing Categorical Data" by Jeffrey S. Simonoff.
Binary Jar file
Source incl. JavaDoc
rapidminer-mlwizard-5.2.002-src.zip
The source can be compiled using ant and the the provided build.xml Therefore, you need to have the RAPIDMINER_HOME environment variable set to your RapidMiner location or you have to adjust the build.xml file and set the rm.dir variable correctly. Then, you can create the MLWizard jar-file by:
:$ ant createJar
Usage
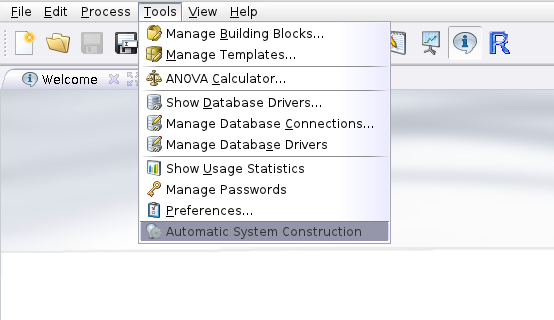
The wizard can be found within the Tools menu in the menu bar of RapidMiner:
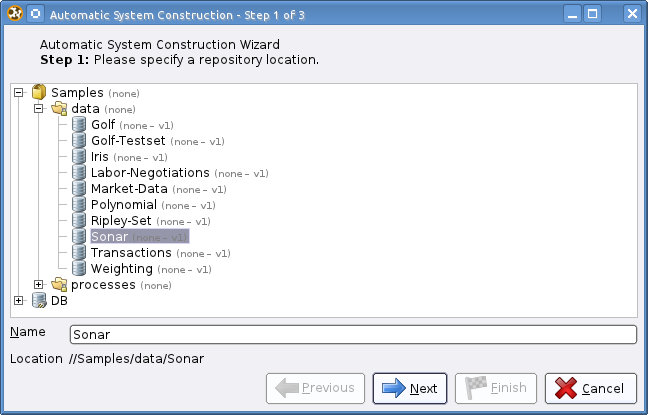
Step 1: Dataset Selection
First, a dataset has to be selected from any repository of RapidMiner;
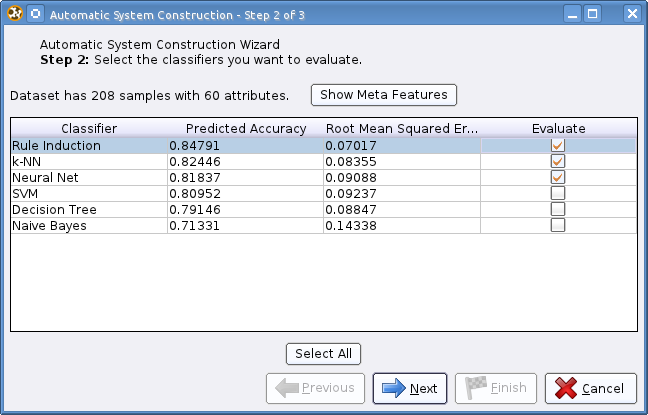
Step 2: Evaluation Selection
After the dataset has been analyzed, the predicted accuracies of the classifiers are shown. Now, the classifier that should be actually evaluated on the dataset have to be selected:
Step 3: Classifier Selection
The evaluation of the classifiers may take some time. After it is finished, the computed accuracies are shown and the classifier on which basis the classification system should be constructed has to be selected:
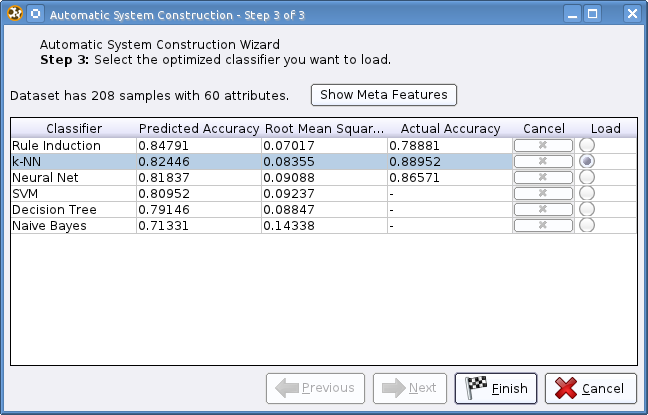
Finally, the system is constructed automatically. If a classifier has been chosen that was also evaluated, the optimized parameter values have been already set. Otherwise, default values are used.
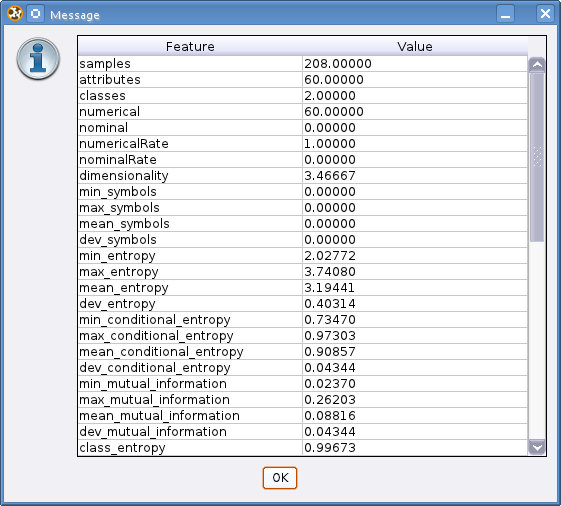
It is also possible to look at the meta-features of the datasets. These are the properties of the dataset used for the classifier recommendation and the parameter optimization.